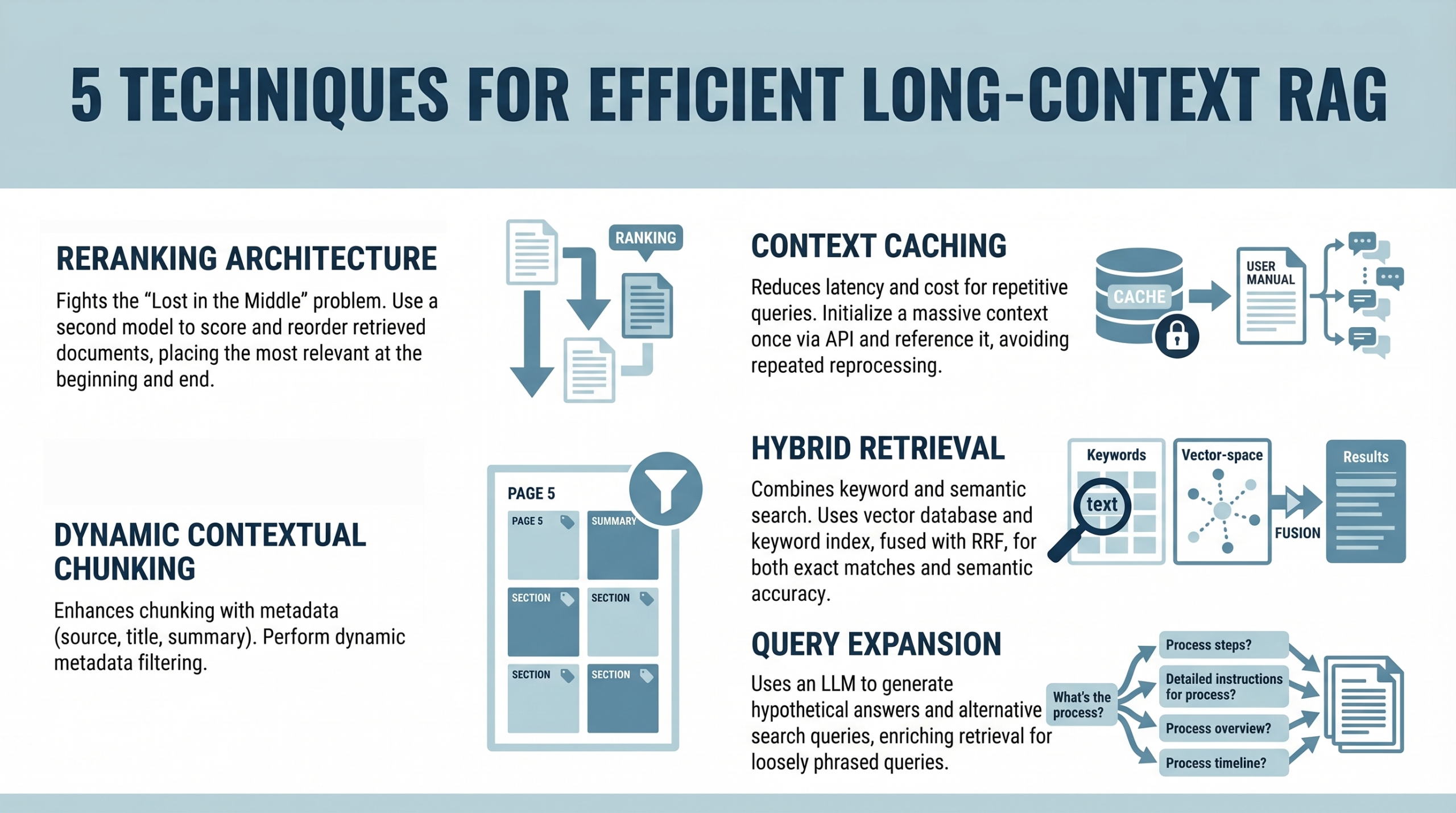
TopList: 5 Techniques for Efficient Long-Context RAG
Machine Learning Mastery compiles a focused TopList of techniques for efficient long-context retrieval-augmented generation (RAG). The list cuts through hype with concrete, applicable guidance for engineers building production-grade AI systems that must reason over long documents, keep context across interactions, and manage memory and retrieval latency. The article emphasizes practical design patterns such as chunking strategies, efficient embedding strategies, cache locality, and streaming results—each contributing to more robust, scalable AI systems. While the TopList is technical, it’s also highly actionable for teams implementing AI copilots, documentation assistants, or enterprise data bots that must stay coherent when the context balloons beyond short sessions.
For practitioners, this is a reminder that performance is not only about model size but about the end-to-end architecture: retrieval pipelines, memory management, and efficient embeddings. The guidance aligns with broader industry moves toward reliable, auditable AI in production, including governance, data provenance, and robust monitoring. The work signals that even as models become more capable, careful engineering remains essential to delivering consistent, trustworthy AI results in real-world settings.
Key themes: RAG, long-context, retrieval, embeddings, production AI.