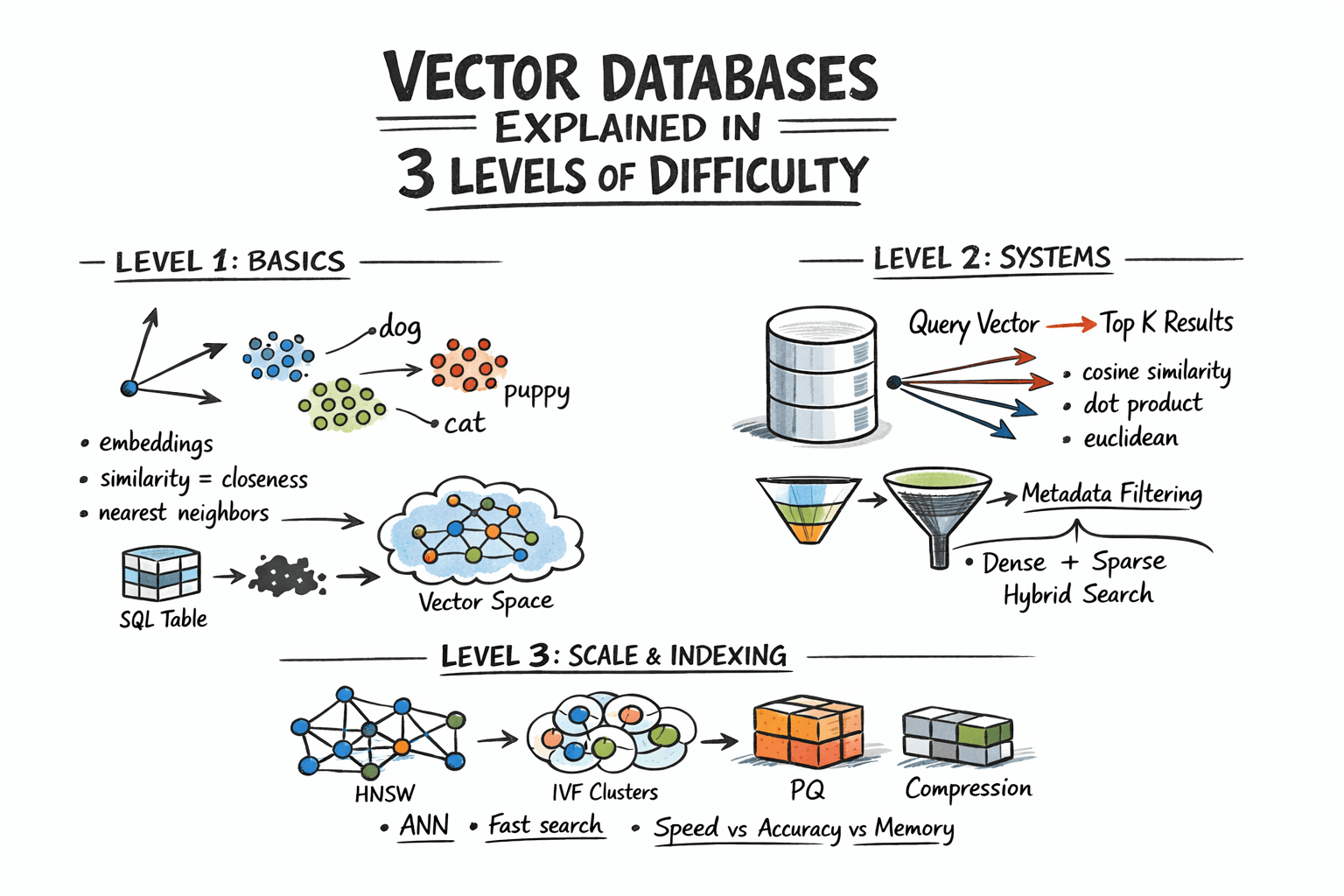
Vector Databases Explained in 3 Levels of Difficulty
Vector databases are foundational to modern AI workflows, powering similarity search, context-aware retrieval, and efficient embedding storage. This explainer breaks down the concepts into beginner, intermediate, and advanced levels, helping engineers decide when to adopt vector storage, how to index vectors efficiently, and how to balance latency with accuracy. The broader implication is clear: as AI systems rely more on retrieval-augmented generation, the data layer becomes a prime candidate for optimization, governance, and performance tuning. The article situates vector databases as essential infrastructure for RAG (retrieval-augmented generation) pipelines, enabling faster, more relevant responses without sacrificing scale.
For practitioners, the practical lessons include selecting the right embedding models for your domain, tuning vector indexes for search latency, and ensuring robust data lineage and access controls around embeddings. Governance considerations—data provenance, privacy, and model-to-data traceability—become increasingly important as vector databases grow in importance for enterprise AI. The takeaway is that vector storage is not merely a backend choice; it’s a strategic component of AI system design that shapes how effectively an organization can scale retrieval-based AI experiences.